High Quality AI Stem Splitting: How to Extract Clean Stems With SAM Audio and Demucs
Every music producer, DJ, and content creator has faced the same frustrating problem. You need that perfect acapella for a remix, a drumless track for practice, or an isolated guitar riff for sampling. But traditional stem splitting leaves you with muddy vocals, ghostly drum artifacts, and disappointing results.
What if you could extract any instrument from any song with improved clarity? Modern AI stem splitting services have made this possible. By combining Meta's SAM Audio with the established capabilities of Demucs, you can now isolate vocals, drums, bass, or custom instruments with higher fidelity than previous methods allowed.
In this guide, you'll learn what stems are, why most stem splitters introduce artifacts, and how to get high quality stems for real production work. Whether you're extracting better Suno stems or creating clean instrument tracks for remixes, this is your technical roadmap to improved audio separation.
What Are Stems? Understanding Audio Separation Basics
Before diving into advanced techniques, let's answer the fundamental question: what are stems?
Stems are individual audio tracks extracted from a mixed song. Think of them as the building blocks of a recording. Instead of one stereo file containing everything, you get separate files for vocals, drums, bass, piano, and other instruments. Each stem contains only that specific element.
Note that there are dry stems (without any audio effects) and wet stems (with audio effects applied, such as reverb, compression, and so on). Dry stems are like ingredients before being cooked, while wet stems are the dishes in your meal. In this article, the models we mention can only extract wet stems, i.e. with effects applied.
Why Stems Matter for Modern Music Production
Stems transform a static stereo mix into flexible parts. When you have high quality stems, you can:
- Create karaoke tracks by removing vocals
- Produce mashups with clean acapella isolation
- Rebalance mixes by adjusting individual instrument levels
- Learn songs by soloing specific parts
- Sample elements without bleed from other instruments
- Fix problematic frequencies in isolated tracks
Traditional stem splitting relied on frequency masking and phase cancellation, which created artifacts and never achieved true isolation. AI changed this by learning to recognize timbre and harmonic structure rather than just filtering frequencies.
The Problem with Most Stem Splitting Services
Not all AI stem splitters deliver equal results. Many services promise "high quality" but compromise on technical fundamentals:
Playgrounds vs Production Tools
Meta's SAM Audio playground, while technically advanced, can only process 30 second clips in mono. This works for demos but fails when you need full song processing in stereo.
Single Model Limitations
Many services use just one AI model, forcing trade-offs. Demucs excels at preset separations (vocals, drums, bass, other) but can't extract custom instruments like saxophone or synthesizer. Other models might offer custom extraction but lack the separation quality of specialized tools.
No Audio Restoration Pipeline
Stem extraction from compressed sources like MP3 or streaming platforms reveals existing artifacts. MP3s cut frequencies above 16 kHz, add quantization noise, and reduce dynamic range. A stem splitter that doesn't address these issues simply isolates damaged audio more clearly.
How SAM Audio Advances Stem Splitting
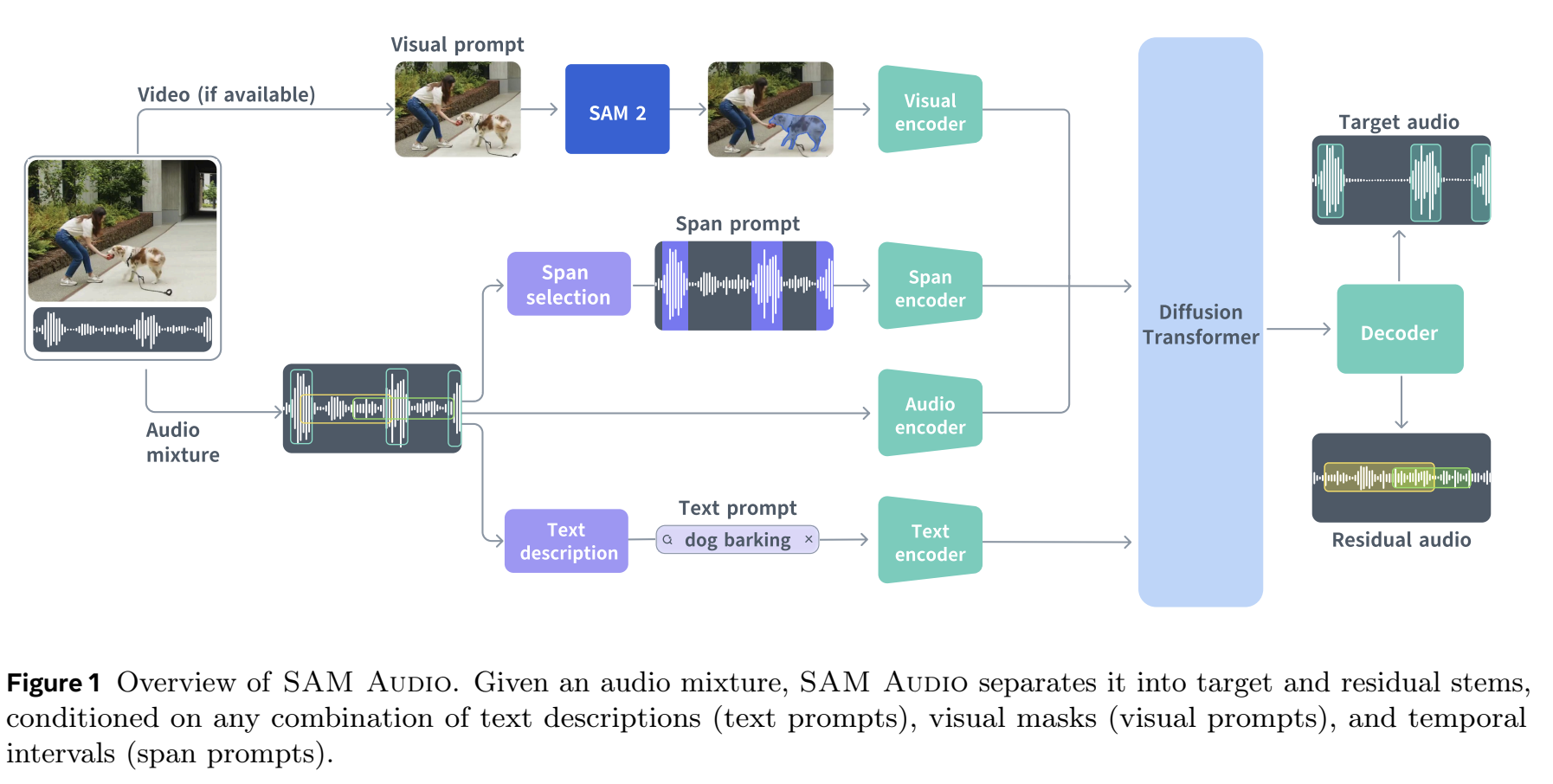
Meta's SAM Audio is a flexible source-separation model, not just another vocal remover. Meta describes it as a unified model for text, visual, and time-span prompts, built on a flow-matching transformer and trained on large-scale multimodal audio mixtures across speech, music, and general sounds.
See the Difference: SAM Audio vs. Industry Standards
Below is a real-world comparison. We took a complex classical mix and attempted to isolate the Piano stem using SAM Audio (Neural Analog) versus a leading competitor.
Example: Piano Extraction Comparison
Isolating a single instrument from a dense stereo mix using the prompt 'piano'.
The Technology Behind SAM Audio
SAM Audio uses a flow-matching transformer architecture to predict the target source from a mixed audio scene. In practice, that means you can ask for a source by text, mark a time span where it appears, or use visual context when the system supports it. The important difference for producers is control: the model can target sounds that do not fit the old fixed categories of vocals, drums, bass, and other.
The Neural Audio Encoder: Why Model Architecture Determines Quality
At the heart of every AI stem splitter lies a neural audio encoder. This component transforms raw audio waveforms into compressed representations that capture timbre, pitch, rhythm, and spatial characteristics. Think of it as the model's "ears": its ability to distinguish a snare drum from a vocal depends on how well this encoder was trained.
Early separation models used simple CNN encoders that processed spectrograms like 2D images. While effective for basic tasks, these encoders struggled with fine timbral details and temporal consistency. Modern models like Demucs employ multi-band encoders that analyze different frequency ranges independently, preserving phase relationships critical for natural sound.
SAM Audio represents a leap forward with its Perception Encoder Audiovisual (PE-AV), trained on over 100 million video clips. This encoder understands the relationship between visual and auditory information. When you prompt it to extract "guitar", PE-AV draws on its knowledge of what guitars look like being played, how they're mic'd in studios, and how their harmonic structure evolves. This multimodal understanding enables more precise separation, especially for instruments that share frequency ranges with other sources.
The encoder's quality directly impacts stem quality in three ways:
- Timbre resolution: Better encoders distinguish harmonics from noise, preserving instrument character
- Temporal coherence: Advanced encoders maintain consistent separation across time, avoiding the "chattering" artifacts common in cheaper tools
- Feature richness: Large encoders capture subtle details like string squeaks, breath sounds, and room ambience
Each new model iteration innovates primarily by improving this encoder architecture. When evaluating stem splitting services, the encoder architecture matters more than marketing claims. A model using a 2020-era encoder cannot match the quality of one built on PE-AV or similar modern architectures, regardless of post-processing tricks.
How Neural Analog Builds on SAM Audio and Demucs
Neural Analog leverages SAM Audio to create a practical pipeline for musicians.
Unlike the 30-second mono SAM Audio official playground, Neural Analog processes complete tracks in full stereo. Stems maintain spatial width and depth essential for modern production.
Neural Analog lets you choose between SAM Audio and older, battle-tested Demucs-style presets:
- SAM Audio for flexible custom instrument extraction (saxophone, synthesizer, strings)
- Demucs for faster, reliable preset separations (vocals, drums, bass, other)
For SAM Audio workflows, you can prompt the model and mark spans in the waveform when the target sound only appears in part of the track. Join our Discord to explore together the future of stem splitting!
Integrated Audio Restoration Pipeline
You can run extracted stems through audio restoration to increase frequency range and touch up some of the artifacts.
Better Suno Stems: Why AI-Generated Music Needs Special Treatment
Suno and other AI music generators, including Udio and FlowMusic / Producer.ai, can create impressive compositions but often output compressed or bandwidth-limited files. That creates a quality ceiling before stem splitting even begins.
The Double Compression Problem
Extracting stems from Suno MP3s using basic tools separates already-compromised audio. The result has:
- Severe high-frequency loss (often nothing above 15 kHz)
- Quantization noise embedded in the signal
- Reduced stereo width and depth
- Digital "ringing" artifacts
How Restoration Improves AI-Generated Music
The process specifically addresses AI music limitations:
- Initial Extraction: SAM Audio or Demucs separates stems
- Artifact Removal: Neural restoration identifies and removes MP3 compression noise
- Frequency Reconstruction: AI predicts and regenerates harmonic content up to 20 kHz
- Stereo Enhancement: Width and depth are restored based on patterns from professional recordings
The result is Suno stems that more closely resemble professionally recorded multitracks.
Step-by-Step: How to Get High Quality Stems Using Neural Analog
Here's the workflow for consistent results:
Step 1: Upload Audio
Drag and drop your file or paste a supported public link from Suno, Udio, FlowMusic, TopMediaAI, Treblo, Mureka, or YouTube. Supported upload formats include MP3, WAV, FLAC, M4A, and OGG. Maximum duration depends on your plan and the selected model.
Step 2: Choose Separation Strategy
For predictable results: Use presets (Vocals, Drums, Bass, Other). These use Demucs and deliver consistent separation.
For custom instruments: Select "Custom Instrument" and type your description. Be specific: "electric guitar solo with distortion" beats "guitar".
Step 3: Configure Processing
Stereo Processing: Default maintains full stereo imaging, processing the Mid section and Sides independently. Change to Mono or to Left/Right processing depending on the instrument.
Step 4: Process and Download
Click "Extract Stems" and wait for processing. Short tracks often finish in a few minutes, while longer tracks and heavier models can take longer. You'll receive individual files for each stem with waveform and spectrogram tools in Studio.
Step 5: Restore the Extracted Stems
Like what you hear? Click "Restore audio" to upscale the audio and rebuild missing high-frequency detail before exporting.
Technical Considerations for Production Workflows
When integrating stem extraction into your production pipeline, consider these factors:
Source File Quality
While restoration can rebuild compressed files, starting with lossless sources (WAV, FLAC) provides more accurate separation. The encoder has more original information to work with, reducing the amount of reconstruction needed.
If your instrument only appears in a few seconds of a long audio file, mark the relevant span in Studio or trim the file before uploading. This makes the target clearer for the model and faster to process.
Stem Phase Coherence
Multiple stems from the same song should sum to the original mix (or close to it). Neural Analog's models maintain phase relationships, ensuring that recombining stems doesn't introduce comb filtering or cancellation. This is critical for stem mastering and remixing.
Artifact Audibility
Listen for common separation artifacts:
- Bleed: Instruments appearing faintly in the wrong stem
- Chattering: Rapid switching on/off during extraction
- Smearing: Loss of transient sharpness
- High-frequency loss: Lack of air and detail
The restoration pipeline addresses many of these, but starting with clean sources minimizes them at the extraction stage. We also recommend you to use a DAW afterwards to cut which part of the stem you like.
When to Use Each Model Type
Use Demucs (Presets) When:
- You need standard vocal, drum, or bass isolation
- Processing speed is critical
- The source mix is relatively clean
- You want predictable, tested results
Use SAM Audio (Custom) When:
- The instrument isn't covered by standard presets
- The mix is dense and overlapping
- You need to separate similar sounds (e.g., lead guitar vs. rhythm guitar)
- The source contains unusual instruments or synthesized sounds
Always Use Restoration When:
- Source is MP3 or streaming audio
- The original file is below 320 kbps
- You're extracting from AI-generated music
- The stems will be used in commercial releases
How to Choose the Best AI Stem Splitting Workflow
Start with a test track to familiarize yourself with the workflow. Compare extracted stems against your original mix to verify phase coherence and artifact levels. Once comfortable, integrate stem extraction into your regular production process for remixes, samples, and mix analysis.
With modern AI models and proper restoration, extracted stems can approach the quality of original multitrack sessions, opening new creative possibilities for producers, DJs, and musicians working with any source material.