AFTER Model Explained: Real-Time Neural Audio Control by IRCAM
AFTER is a neural audio synthesis model designed to give musicians precise, real-time and polyphonic command over neural synthesis using familiar tools like MIDI and audio descriptors.

What is the AFTER Model?
AFTER stands for Audio Features Transfer and Exploration in Real-time. It is a neural audio synthesis framework that solves a specific challenge: decoupling musical expression (structure) from sound identity (timbre), allowing you to manipulate both independently.
Unlike previous "black box" models that output sound based on abstract latent coordinates, AFTER is built to be steerable. It allows you to take the performance nuances of one instrument (like the pitch curve of a voice) and apply them to the learned timbre of another, or to drive a neural synthesizer entirely via MIDI.
History and Origin: The ACIDS Team
AFTER is the result of the PhD research of Nils Demerlé at IRCAM (Institute for Research and Coordination in Acoustics/Music) in Paris. Working within the ACIDS group alongside researchers Ninon Devis, Philippe Esling, Guillaume Doras, and David Genova, the team sought to overcome the limitations of Variational Autoencoders (VAEs).
While VAEs (like the RAVE model) are great for compression, they often struggle to separate pitch from timbre cleanly due to "entanglement." The team presented their solution in the paper "Combining audio control and style transfer using latent diffusion" in August 2024. Their goal was to harness the high-fidelity quality of diffusion models and optimize them for live musical performance.

AFTER Architecture: Latent Diffusion
The architecture of AFTER relies on Conditional Latent Diffusion. Instead of generating raw audio samples one by one (which is slow), it operates in a compressed "latent" space provided by a pre-trained autoencoder.

The "Skeletal" Approach: Structure vs. Timbre
The core philosophy is the strict separation of sound into two streams:
- The Structure (Local Features): Explicit, time-varying controls.
- Audio Input: Pitch (f_0) and Loudness (A-weighted).
- MIDI Input: Polyphonic piano roll representation.
- The Timbre (Global Features): A learned static embedding vector that represents the sonic identity (e.g., "Cello", "Distorted Guitar").
How the Network Functions
- Compression (The Codec): Incoming audio is compressed using a Neural Audio Codec (typically a RAVE autoencoder model) into low-dimensional latent vectors.
- Conditioning: The system extracts pitch/loudness curves (using tools like CREPE or Basic Pitch) to create the structural condition.
- Latent Diffusion: A conditional U-Net predicts the audio latents based on the structure and the target timbre.
- Decoding: The audio codec decodes the predicted latents back into raw waveforms.
How to Train AFTER Models
Training is divided into three distinct stages. You can find the full scripts in the GitHub repository.
1. Dataset Preparation
You need a dataset of audio samples (typically >1 hour for good results).
- Preprocessing: The
after prepare_datasetscript analyzes audio to extract ground truth features. - Tools: It uses Basic Pitch (by Spotify) for MIDI transcription and loudness extractors for audio. The data is stored in an LMDB database for high-speed access during training.
2. Autoencoder Training (The Codec)
Before training the diffusion model, you need a "codec" to compress audio.
- Option A: Train a new causal autoencoder using Multi-scale Spectral Loss and Adversarial Hinge Loss.
- Option B: Use a pre-trained RAVE model as the backend. This is faster if a good model for your domain already exists.
3. Diffusion Model Training
This is where the model learns the relationship between control signals and sound.
- The Objective: The model minimizes a Noise Prediction Error (MSE)—essentially learning how to remove noise from the signal to reveal the target sound.
- Disentanglement: Crucially, it employs an Adversarial Criterion during training. This penalizes the model if the "Timbre" encoder accidentally learns information about the pitch, ensuring the two controls remain totally independent.
Inference: Max for Live and Real-Time Usage
Max for Live (M4L) Integration
For Ableton Live users, AFTER provides two Max for Live devices that handle the communication with the neural engine.
The first is Audio-to-Audio. It uses a side-chain input (e.g., your voice) to drive the pitch and loudness of the neural model.
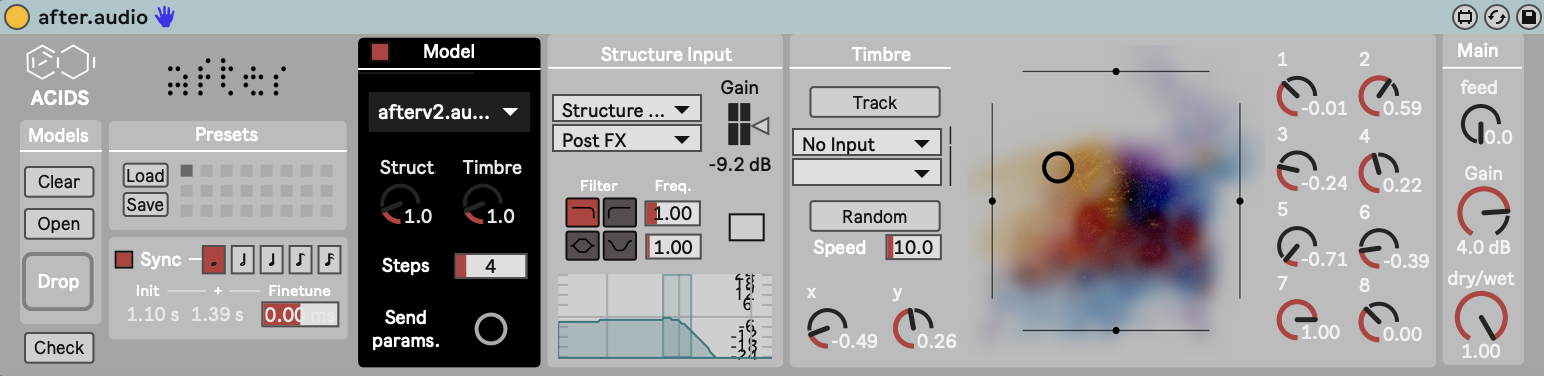
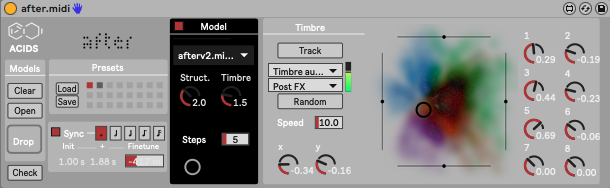
The second is MIDI-to-Audio. It converts MIDI notes into the required pitch/loudness curves to drive the model. Thanks to the latent diffusion architecture, this supports polyphony if trained on polyphonic data.
Max/MSP and nn~
For developers, AFTER runs inside Max/MSP using the nn~ external. This allows you to load the exported TorchScript models (.ts files) directly into a patching environment.
Performance & Latency
Because AFTER uses diffusion, it functions differently from instantaneous feed-forward models like RAVE.
Latency: Diffusion requires iterative steps (denoising) to generate sound. In the real-time implementation, this typically results in a latency between 200ms and 500ms. It is "real-time" in the sense that it generates audio on-the-fly, but it feels more like playing a predictable delay than an instant instrument. For some live performances, some artists choose a "looper" approach (have AFTER play the phrase on the next loop cycle) instead of immediate response.
GPU utilization: The model inference rests on nn~, which supports GPU acceleration, but in practice users notice little difference. Moreover, the iterative nature of diffusion means CPU usage will still be significant compared to standard DSP.