RAVE Model Explained: Real-Time Neural Audio by IRCAM
RAVE is a real-time neural audio model for musicians, sound designers, and researchers who want to train playable AI instruments. It compresses sound into a learned latent space, lets you manipulate that space, and decodes the result fast enough for DAWs, Max/MSP, Pure Data, and embedded workflows.

What Is IRCAM RAVE for Real-Time Audio Synthesis?
RAVE stands for Realtime Audio Variational autoEncoder. Released in November 2021 by researchers at IRCAM in Paris, it's essentially a clever compression algorithm that learns to "understand" sounds and then recreate them from a compact digital representation. Think of it like teaching a computer to sketch what it hears, then redraw that sketch as a convincing imitation of the original sound.
The magic? It does this fast enough to work in real-time inside your DAW or live performance setup.
Who Created RAVE and When?
RAVE was developed by Antoine Caillon, who now works for Google DeepMind, and Philippe Esling at IRCAM's ACIDS team in Paris.
The team had previously explored Google's DDSP (Differentiable Digital Signal Processing) model, even showcasing it in March 2021, but wanted something more flexible that could handle any type of sound—not just musical instruments.
Their goal was simple: create a model that could run on standard hardware while delivering studio-quality audio. The model was first presented in their 2021 paper, "RAVE: A Realtime Audio Variational Autoencoder for End-to-End Neural Audio Synthesis".
RAVE Architecture: How This Variational Autoencoder Works
At its core, RAVE is an autoencoder, a type of neural network that learns to compress data into a compact "latent space" and then decompress it back.
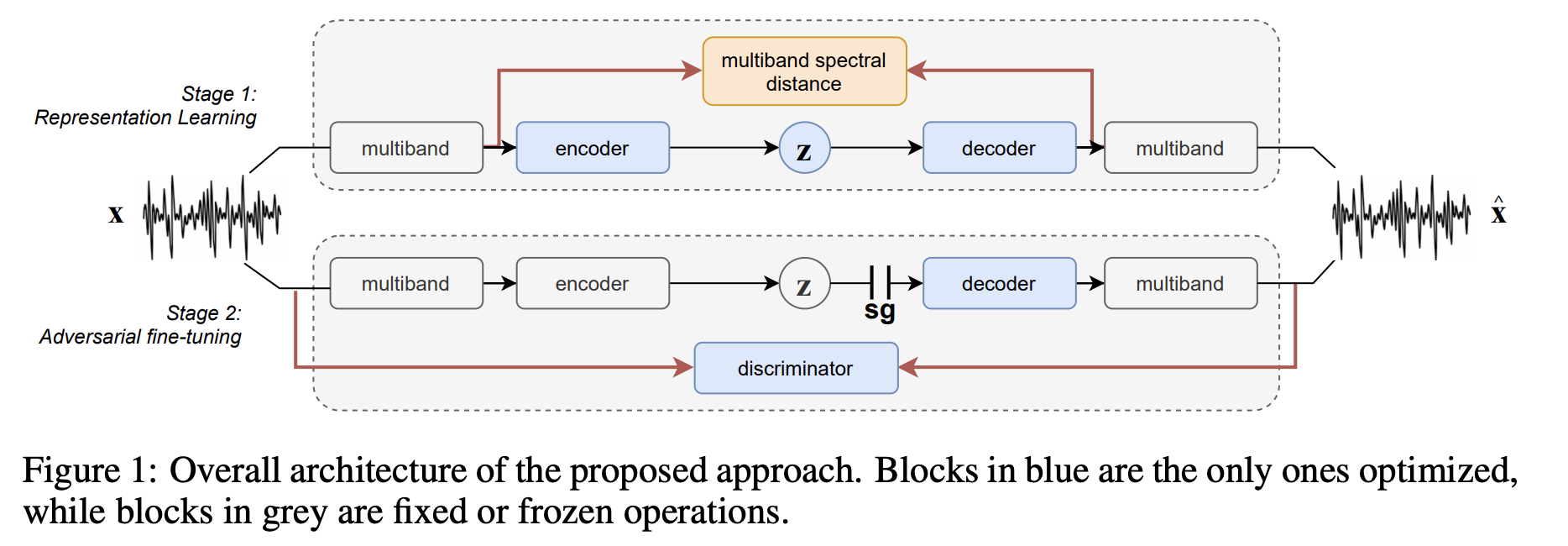
The Two-Stage Training Process
Imagine training a musician in two phases:
-
Phase 1: Learning to Listen (Representation Learning)
- The encoder learns to squeeze audio into a tiny mathematical fingerprint (the latent space)
- The decoder learns to reconstruct audio from these fingerprints
- This is done using spectral loss—basically comparing the frequency content of original vs. reconstructed audio
-
Phase 2: Learning to Improvise (Adversarial Fine-Tuning)
- The encoder is frozen (it knows how to listen)
- A "discriminator" network is introduced—think of it as a critic that judges if the reconstructed audio sounds real
- The decoder improves through this feedback, learning to create more convincing audio
Key Technical Components
- PQMF Filters: RAVE splits audio into multiple frequency bands before processing, making it more efficient
- Causal/Non-Causal Modes: You can trade some quality for lower latency in live settings
- Multiple Configurations: From lightweight "raspberry" (runs on Raspberry Pi) to high-quality "v3" for serious training
For detailed implementation of the architecture, refer to the official RAVE GitHub repository which includes configuration files and model definitions.

How to Train RAVE Models on Custom Audio Data?
Ready to create a model that turns your voice into a saxophone? Training RAVE models requires Python coding knowledge and access to GPU resources. The official RAVE repository provides comprehensive documentation for the technical implementation.
Dataset Preparation Requirements
To train a RAVE model, you'll need:
- 2-3 hours of clean audio (more is better!)
- Studio-quality recordings since RAVE learns everything, including noise and reverb
- Diverse sounds if you want versatility
The preprocessing involves converting your audio files into RAVE's specific format. For detailed preprocessing commands and parameters, check the RAVE documentation. Note that lazy loading is available but increases CPU load during training significantly.
RAVE Training Process and Configurations
The training process involves multiple phases and configurations. RAVEv2 offers several architecture options including v1, v2, v2_small, v3, discrete, and specialized configurations for different hardware requirements. Each configuration has specific GPU memory requirements ranging from 5GB for Raspberry Pi-compatible models to 32GB for v3. You need about 2-3 hours of clean audio for effective training.
What to expect during training:
- Phase 1 (~1M steps): Audio quality starts rough and gradually improves
- Phase 2 (adversarial training): Quality improves dramatically
- Total time: ~3 days on an RTX 3080 GPU
Community-contributed training notebooks provide step-by-step guidance for the technical implementation.
Exporting RAVE Models for Real-Time Use
The export process is critical for real-time applications. Use the --streaming flag to enable cached convolutions and prevent clicking artifacts. For detailed export parameters and troubleshooting, refer to the export documentation.
RAVE Model Inference and Real-Time Usage Options
Don't want to wait 3 days for training? Try pretrained RAVE models right now through several platforms.
Neutone FX: Free VST/AU Plugin for RAVE Models
Neutone FX is a free VST/AU plugin that hosts RAVE models. It's the original Neutone plugin from 2022, now maintained as an open platform. Download the plugin from the Neutone website to load a collection pretrained models directly in your DAW (Ableton, Logic, Reaper, etc.).

Max/MSP and PureData Integration with nn~
For live performance applications, the nn~ external lets you load RAVE models directly in Max/MSP and PureData. This enables advanced techniques including direct latent space manipulation and Adaptive Instance Normalization for style transfer. This integration even supports embedded platforms like Raspberry Pi for portable installations.
RAVE Performance Limitations and Technical Caveats
RAVE is powerful, but it's not perfect. Here are the real-world issues you should know about.
- Latency: Even with causal mode, expect meaningful delay on high-end Apple Silicon hardware. Fine for studio use, but test carefully before using it as a live instrument.
- GPU Acceleration: Surprisingly, the model's convolutional architecture doesn't parallelize as well as you'd expect. The model uses many small convolutions that are memory-bound rather than compute-bound. Moving to GPU adds overhead that often outweighs benefits unless you're batch-processing.
- Audio Quality: While RAVE can produce impressive results, it may not match the fidelity of traditional synthesis methods or high-end neural models like diffusion-based approaches.
- Difficult to Train: Training RAVE models requires expertise in machine learning, audio processing, and access to strong hardware.
RAVE Follow-Ups: Neutone Morpho and AFTER Model
Neutone Morpho: Commercial Evolution of RAVE (2024)
In February 2024, the Neutone team led by Nao Tokui released Morpho, a commercial evolution of their free FX plugin. While RAVE is the open-source research engine, Morpho packages similar technology into a polished product designed for musicians and producers, at the price of less flexibility.
AFTER Model: Diffusion-Based Alternative from IRCAM
The same IRCAM ACIDS team has also released AFTER (Audio Features Transfer and Exploration in Real-time), a diffusion-based model. The goal is to make a more "tweakable" model that allows real-time control over timbre, like a traditional synthesizer.