DDSP: Differentiable Digital Signal Processing for Neural Audio Synthesis
DDSP (Differentiable Digital Signal Processing) is a machine learning framework from Google's Magenta research lab that combines classical digital signal processing with deep neural networks.
Unlike black-box models that generate audio from scratch, DDSP uses interpretable DSP components (oscillators, filters, and reverb) controlled by neural networks to create realistic instrument sounds. This approach enables high-quality timbre transfer using as little as 10 minutes of training data per instrument.
History and Evolution: From Magenta to Modern Plugins
Magenta Research Lab (2016-2024)
Google's Magenta launched in 2016 as an open-source research project exploring AI's role in creative processes. The lab produced numerous tools for music generation, but most projects have been archived as of 2024, reflecting both the rapid evolution of AI audio technology and shifting research priorities.
Open NSynth Super (2017)
Before DDSP, Magenta introduced Open NSynth Super, a hardware instrument built around the NSynth dataset, made out of 305 000 single-note samples from 1006 instruments. The device allowed real-time exploration of sonic interpolations using a Raspberry Pi and a custom PCB.

The NSynth algorithm, based on WaveNet's temporal encoder, was limited to 16-bit/16kHz audio due to computational constraints. This resulted in perceptibly lo-fi output. Audio engineer Joe Boston noted the "grainy" quality but discovered creative applications through external effects processing. The hardware project was archived in August 2025.
DDSP and Tone Transfer (2020)
In 2020, Magenta published the DDSP library and accompanying ICLR paper, introducing differentiable versions of signal processing modules. The Tone Transfer web demo showcased the technology, enabling users to transform vocal recordings into violin, saxophone, trumpet, or flute.
The models used RNN-based autoencoders trained on approximately 10 minutes of monophonic audio per instrument. While the demo worked, the 16kHz output quality and limited articulation modeling left room for improvement.
MIDI DDSP and VST Plugin (2022-2024)
Magenta extended DDSP with MIDI DDSP in January 2022, enabling direct MIDI-to-audio synthesis. The plugin processed monophonic MIDI sequences into instrument sounds.
In June 2022, Magenta released the DDSP VST plugin, allowing real-time timbre transfer in DAWs. Both projects were archived in 2024 (MIDI DDSP in February, VST in October).

MAWF Audio Plugin (2023)
Hanoi Hantrakul (yaboihanoi), former tech lead on Tone Transfer and ByteDance employee since 2020, launched MAWF in 2023. This free VST/AU plugin delivers real-time neural audio synthesis at 48kHz, overcoming the 16kHz limitation of earlier DDSP implementations.

Architecture: Autoencoders Meet DSP
DDSP employs a neural autoencoder architecture that replaces the conventional waveform generator with modular DSP components.
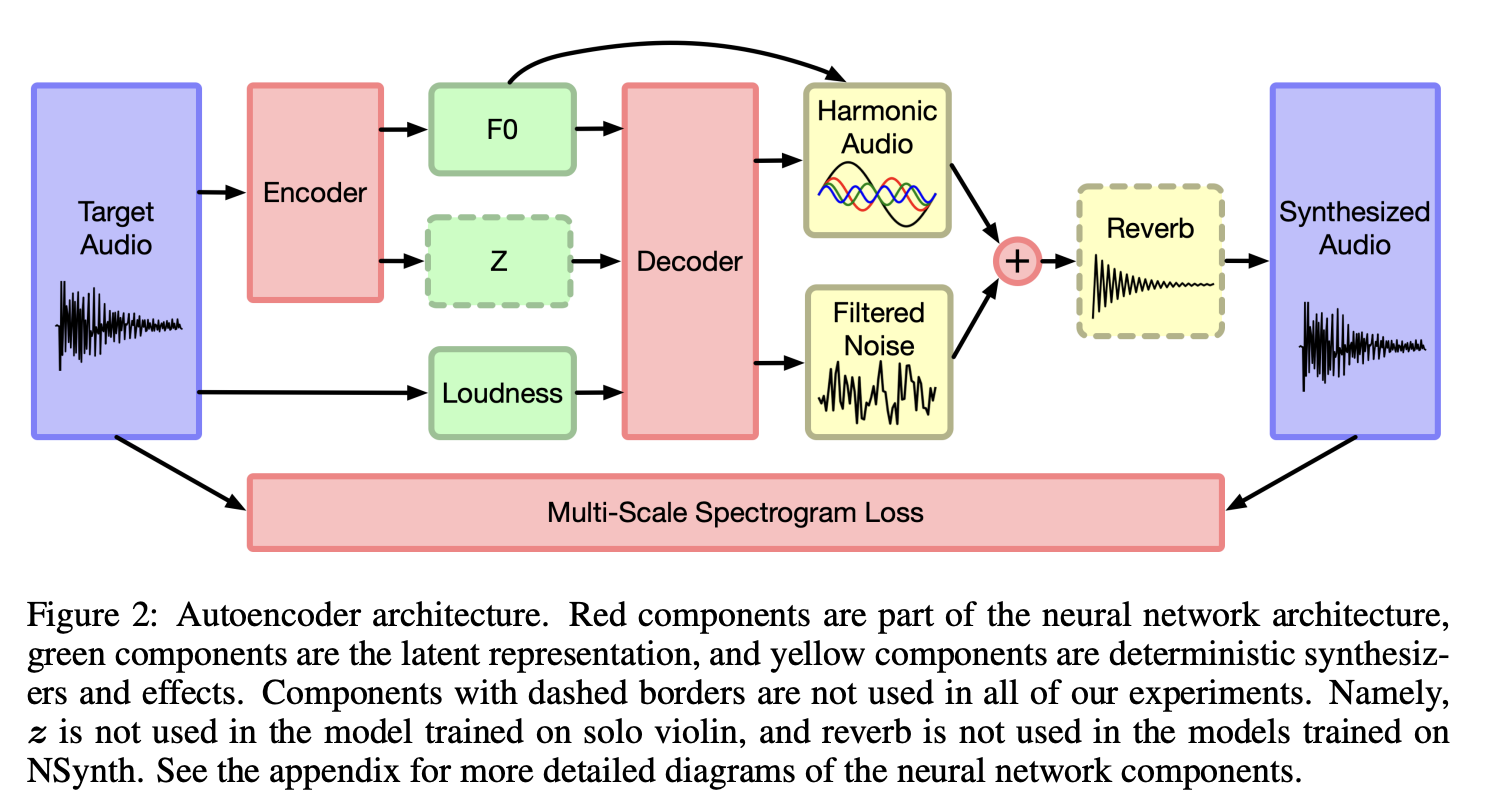
Encoder Network
An RNN (typically a GRU) analyzes input audio to extract fundamental frequency (f0, the pitch) and loudness contours. These low-dimensional control signals capture the essential performance dynamics.
Decoder and Synthesis Modules
The decoder maps control signals to parameters for three DSP components:
- Harmonic Additive Synthesizer: Generates up to 100 sinusoidal partials based on fundamental frequency, creating pitched content
- Filtered Noise Synthesizer: Uses time-varying FIR filters to shape white noise, modeling breath and bow noise
- Differentiable Reverberator: Adds room acoustics with learnable parameters
All components are fully differentiable, enabling end-to-end training via spectrogram loss. The model learns to adjust hundreds of synthesis parameters frame-by-frame, producing realistic timbre without generating audio sample-by-sample.
Training Your Own DDSP Model
Magenta provides Colab notebooks for training custom instruments. You need approximately 10-15 minutes of clean, monophonic recordings and basic Python coding skills to run the notebook. The process involves data preprocessing, configuration, and several hours of GPU training on Google Colab.
Real-Time Implementation Options
Despite the archived status of official Magenta projects, several tools make DDSP accessible:
1. Magenta DDSP VST (Archived)
The official plugin remains functional for experimentation. It includes five instrument models and processes both MIDI and audio input. Users report noticeable reverb processing to mask artifacts.
2. Neutone FX Platform
Neutone.space offers a free plugin for hosting community-trained models, including DDSP-based timbre transfer networks. The platform connects AI researchers with audio producers, providing dozens of models beyond the original Magenta instruments.

3. MAWF by yaboihanoi (Recommended)
The MAWF plugin delivers professional-grade DDSP synthesis at 48kHz with modern DAW integration. It includes multiple instrument models and represents the most polished implementation of the technology.

However, the MAWF website to download the plugin is down as of November 2025.
Technical Limitations and Caveats
DDSP has several inherent limitations stemming from its architecture and synthesis approach:
- Monophonic DDSP models were trained on single-note instruments and can't generate polyphonic audio. This is because they were trained over monophonic datasets, and the harmonic synthesizer assumes a single fundamental frequency at each time step.
- Audio Quality While MAWF's 48kHz models improve fidelity, the original 16kHz implementations exhibit metallic artifacts and limited high-frequency content.
- No GPU Parallelization The RNN-based architecture prevents efficient batch processing on GPUs, limiting real-time performance for complex tasks.
- mawf.io website is down as of November 2025, possibly due to hosting issues. I'll update this article if I find an alternative source for the plugin.
Beyond DDSP
RAVE (2021)
RAVE replaced RNNs with causal CNNs, enabling faster training, 48kHz synthesis, and improved timbre modeling. The model uses a variational autoencoder with discriminator training, producing higher fidelity with similar data efficiency.
DDSP-CNN-Tiny (2022)
DDSP-CNN-Tiny is an optimization of DDSP that swaps RNNs for lightweight CNNs, reducing model size and inference time. It maintains comparable audio quality while enabling real-time CPU performance. The model was developed by Václav Volhejn during his thesis at ETH Zurich, which is a great technical read.
AFTER (2024)
The AFTER model combines diffusion principles with neural audio coding for production-quality synthesis. While computationally heavier than DDSP, AFTER achieves near-lossless timbre transfer with minimal artifacts, targeting professional studio applications.